Advanced Техники Помогающие Избегать и Находить Deadlocks в .NET Приложениях.
Оригинал статьи: http://msdn.microsoft.com/ru-ru/magazine/cc163618%28en-us%29.aspxАвтор статьи: Joe Duffy
Автор перевода: Александр Кобелев
Прочитав эту статью, вы разберетесь в причинах возникновения deadlock, узнаете, что они бывают разных типов, и в самом конце будет небольшая пошаговая инструкция, пройдя все шаги которой, вы научитесь находить deadlock в живых .net приложениях.
За основу взята статья Advanced Techniques To Avoid And Detect Deadlocks In .NET Apps. Однако, переведена лишь ее теоритическая часть, оставшаяся часть (использующая C++ и CLR hosting API) доступна в оригинальной статье, вместо нее, вам будет предложена пошаговая инструкция по обнаружению deadlocks без использования C++.
Так же, в тексте статьи вы найдете ссылки на справочные ресурсы, а вот в таких выделенных блоках вы встретите мои дополнительные пояснения.Эта статья рассматривает:
- Причины возникновения deadlocks
- Методику lock leveling, помогающую избегать deadlocks
- Обнаружение deadlocks и их устранение
- Обзор CLR hosting API для подключения и обнаружения deadlocks
Для статьи доступен исходный код: Deadlocks.exe(188 KB) (оригинальный исходный код разработанный под Visual Studio 2005)
Зависшее приложение это одна из самых неприятных ситуаций, с которой пользователь может столкнуться. Их ужасно трудно найти при тестировании перед поставкой приложения, и еще труднее отлаживать после развертывания приложения. В отличие от необработанного исключения, зависание не создает crash dump, и не приводит к срабатыванию специальной логики (например, уведомление разработчика о произошедшей ошибке). Пользователи часто завершают процессы зависших приложений, до того как вы будете в силах получить дамп памяти, для последующего анализа и локализации проблемы.
Зависания могут быть как периодические, так и постоянные, они могут возникнуть как результат медленных Input/Output операций, или при обработке сложных / долгих алгоритмов, так и при взаимоисключающем доступе к ресурсу. В любом случае это снижает отзывчивость приложения и может привести к подвисаниям. К примеру: код, который блокирует выполнение GUI потока, может помешать текущей обработке пользовательского ввода и обработке системных событий, в результате приложение подвиснет и система отобразит его как "Not Responding". Даже программы без графического интерфейса могут страдать от проблем отзывчивости, при использовании общих ресурсов или при выполнении Inter-Thread, Inter-Process или сетевых взаимодействий. Самый худший тип зависания - когда приложение подвисает намертво и никогда не возобновит своей работы, другими словами deadlock.
Разработка приложений с большой конкуренцией, используя стандартные Windows® средства - потоки и блокировки, это задача, гораздо труднее, чем может показаться на первый взгляд. Стоит всего лишь забыть заблокировать данные доступные нескольким потокам и это может привести к необработанному исключению (в лучшем случае), или к повреждению данных.
В первой ступени у ракеты находится 3 двигателя, для отстрела ступени нужно, чтобы все двигатели полностью выработали свое горючее. Когда двигатель вырабатывает горючее, он увеличивает общий счетчик отключившихся двигателей на единицу, изначально счетчик равен нулю. Отстрел ступени происходит как только счетчик достигает значения 3. Счетчик в нашем случае не блокируется, а потоки, которые следят за состоянием двигателей, используют метод Increment.
По поводу методов Increment (i++) и Decrement (i--) в MSDN можно найти следующую информацию:
Методы Increment (i++) и Decrement (i--) увеличивают или уменьшают значение переменной и сохраняют результат в одной операции. На большинстве компьютеров увеличение значения переменной не является атомарной операцией, а требует следующих шагов:
- Загрузить значение из переменной экземпляра в регистр.
- Увеличить или уменьшить значение.
- Сохранить значение в переменной экземпляра.
Исходя из вышесказанного, предположим, что первый двигатель отработал чуть раньше других и успешно увеличил значение счетчика на 1 и теперь он равен 1. Двигатели 2 и 3 одновременно выработали свое горючее:
- Поток двигателя 2 Загружает значение из счетчика(равное 1) в регистр.
- Поток двигателя 2 Увеличивает значение на 1.
- Планировщик потоков прерывает работу потока двигателя 2 и отдает управление потоку двигателя 3 (Второй поток не успевает сохранить измененное значение счетчика)
- Поток двигателя 3 загружает значение из счетчика (равное 1, так как второй поток не успел сохранить измененное значение) в регистр.
- Поток двигателя 3 Увеличивает значение на 1.
- Поток двигателя 3 сохраняет значение(равное 2) в переменной счетчика.
- Планировщик потоков возвращает управление потоку двигателя 2
- Поток двигателя 2 возвращается к тому моменту, где его прервал планировщик потоков и сохраняет значение (равное 2) в переменной счетчика.
- Все двигатели выработали свое горючее, данные счетчика повреждены (ложны), счетчик равен 2, отстрела ступени не происходит, ракета падает...
Существует компромисс между coarse-grained locking (крупнозернистость, http://design-pattern.ru/patterns/coarse-grained-lock.html , плюсы: простота и стойкость данных, минусы: снижает возможность применения параллелизма) и fine-grained locking (мелкозернистость, плюсы: высокая возможность параллелизма; минусы: требует более продуманной архитектуры, большое количество блокировок, больше предрасположено к появлению ошибок). Сегменты кода различной "зернистости", каждый раз, при получении и освобождении блокировок склонны взаимодействовать друг с другом непредсказуемым образом. Если ваша система ничего не делает для сдерживания deadlocks, то даже самые незначительные ошибки, при проектировании блокировок, склонны мешать взаимодействию внутри программы.
Сегодняшние модели программирования, требуют, чтобы программист думал о том, что в течение выполнения программы, методы могут выполняться не по порядку. Когда программа начинает вести себя непредсказуемо, то бывает чрезвычайно сложно воспроизвести шаги, приведшие к инциденту. Deadlocks, более заметны, чем гонка методов (в простейшем случае программа просто повиснет), но так же сложны в локализации проблемы и в устранении. Вы можете найти deadlocks в процессе выполнения тестов, но наиболее вероятно, что большинство из них будет дремать до поставки продукта, и впоследствии будут "радовать" ничего не подозревающего пользователя.
Вы можете бороться с deadlocks, используя комбинацию известных практик и агрессивного тестирования на различных hardware платформах. Самая распространенная из этих дисциплин и является темой данной статьи. Но сначала рассмотрим основы deadlocks.
Deadlocks 101
Deadlock возникает, когда несколько конкурирующих потоков ждут один другого для возобновления своей работы. Если это звучит как парадокс, то так оно и есть.
- Есть 2 общих ресурса А и В
- Есть 2 потока, которым для работы нужны оба ресурса одновременно
- Поток 1 запустился и успел захватить ресурс А
- Поток 2 запустился и успел захватить ресурс В
- Поток 1 не может продолжать своей работы, так как ресурс В ему в данный момент не доступен
- Поток 1 не отпуская ресурс А засыпает, в ожидании освобождения ресурса В
- Поток 2 не может продолжать своей работы, так как ресурс А ему в данный момент не доступен
- Поток 2 не отпуская ресурс В засыпает, в ожидании освобождения ресурса А
- Deadlock!
Существует четыре основных условия, которые должны совпасть, чтобы произошел deadlock:
Система должна поддерживать Mutual Exclusion (Взаимоисключение)
http://en.wikipedia.org/wiki/Mutual_exclusionКогда один поток завладел общим ресурсом, другой поток не может завладеть им. Это относится не только к большинству критических секций, но так же и к GUI в Windows. Каждое окно принадлежит одному потоку, который несет полную ответственность за обработку входящих сообщений. Ошибки с Mutual Exclusion при проектировании, могут привести к потере отзывчивости приложения (в лучшем случае) или к deadlock.
Поток уже владеющий, каким то ресурсом, должен иметь возможность впадать в неограниченное ожидание. Например, когда поток, вошедший в критическую секцию, имеет возможность завладеть еще одной критической секцией, и если она занята - впасть в ожидание. Это вполне ожидаемый результат, если вторая критическая секция удерживается другим потоком.
Ресурсы не могут быть насильно забраны от их текущих владельцев. Однако, в некоторых ситуациях это возможно, когда ссора за ресурс была замечена системой. Например, в сложных системах управления базами данных (СУБД). Но это не выход для блокируемых объектов в управляемом коде.
Условие замкнутого ожидания. Замкнутое ожидание происходит в случае, если цепочка из двух или более потоков ждут освобождения ресурсов заблокированных потоками, находящимися в этой цепочке. Также это относится к одному единственному потоку, если он пытается заблокировать ресурс, который невозможно повторно заблокировать, в этом случае поток сам себе создаст deadlock. Однако большинство ресурсов можно заблокировать повторно, что ликвидирует возможность deadlock в одном потоке.
Любой программист, работавший с пессимистичными алгоритмами ( http://ru.wikipedia.org/wiki/Блокировка_(СУБД) ) должен понимать как происходят deadlocks. Если пессимистичный алгоритм при попытке доступа обнаруживает, что ресурс уже занят, то он переходит в ожидание, и ждет до тех пор, пока ресурс не станет свободным (к примеру, блокировки). В сравнении с оптимистичными алгоритмами, пытающимися выполнить работу с риском возникновения разногласия данных, которые будут выявлены позже, например, при фиксации транзакции. Пессимистичный алгоритм много легче реализовать, потому что он более распространен и уже встроен в платформы, по сравнению с оптимистичными технологиями, как правило пессимистичный алгоритм принимает форму монитора (в C# конструкция lock; Visual Basic® SyncLock) mutex ( http://ru.wikipedia.org/wiki/Мьютекс ) или Win32® CRITICAL_SECTION.
Lock-free ( http://ru.wikipedia.org/wiki/Неблокирующая_синхронизация ) алгоритмы, способные обнаружить и реагировать на конкуренцию за ресурсы, являются довольно распространенными для программного обеспечения системного уровня. Эти алгоритмы часто избегают совместного входа в критическую секцию, выбирая livelock вместо deadlock. Livelock тоже представляет проблему для параллельного кода, однако она вызвана fine-grained конкурентностью. Результат Livelock - программа работает, но вхолостую. Проиллюстрировать эффект можно следующим образом - Двое встречаются лицом к лицу. Каждый из них пытается обойти другого, но сдвигаются постоянно в одну и ту же сторону, и никто из них не может пройти вперед.
Следующая иллюстрация демонстрирует, как может произойти deadlock, вообразите последовательность событий:
- Поток 1 блокирует ресурс А
- Поток 2 блокирует ресурс В
- Поток 1 пытается заблокировать ресурс В, но он уже заблокирован потоком 2 и поток 1 впадает в ожидание, пока ресурс В не освободится
- Поток 2 пытается заблокировать ресурс А, но он уже заблокирован потоком 1 и поток 2 впадает в ожидание, пока ресурс А не освободится
В этом случае потоки заблокируются и никогда не проснутся. Следующий C# код демонстрирует данную ситуацию:
Иллюстрация 2 демонстрирует 6 возможных вариантов гонки потоков между двумя потоками. Только в 2 случаях (1 и 4) не наблюдается deadlock. Очень заманчиво сделать вывод, что deadlock произойдет два раза из трех (по тому, что 4 варианта из 6 ведут к deadlock), но это не так, почти всегда будет срабатывать первый вариант, следующим по статистике четвертый и лишь за тем 2,3,5,6 так как временное окно, необходимое для блокировки сразу двух объектов очень мало (в начале LockA и сразу за этим, без какой-либо другой работы, захватить LockB, или наоборот LockB и сразу же LockA), и вероятность того что потоки стартуют одновременно тоже очень мала.
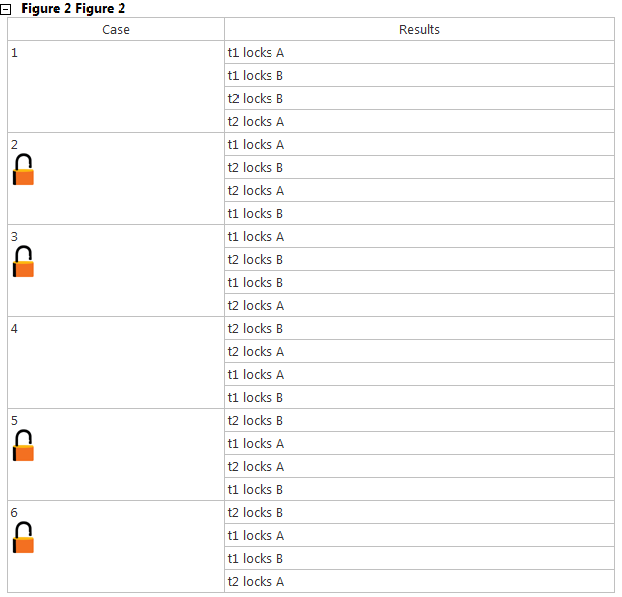
Не заботясь о статистике, если вы будете писать код, как представлено выше, ваша программа всегда будет балансировать на острие ножа. Рано или поздно программа сработает по одному из четырех сценариев ведущими к deadlock, это будет возможно, к примеру из за нового оборудования, которое приобрел заказчик (а вы никогда не тестировали свой продукт с этим оборудованием) или просто статистическая рулетка выдаст один из четырех вариантов.
В приведенном выше примере deadlock достаточно легко идентифицировать и исправить, для этого нужно переписать методы t1 и t2 так, чтобы они захватывали и освобождали блокировки в одном и том же порядке. К примеру с начала всегда захватывается A и лишь за тем B:
Таким образом, мы избавляемся от так называемого «deadly embrace» (смертельное объятие), если всегда захватывать и освобождать ресурсы в одном и том же порядке - deadlock невозможен. Но давайте рассмотрим вариант метода, где возможен deadlock, но он не так очевиден на первый взгляд:
Предположим, кто то пытается перевести $500 с аккаунта #1234 на аккаунт #5678 и в это же время, кто-то другой пытается перевести $1000 с аккаунта #5678 на аккаунт #1234, в этом случае появляются все условия для создания deadlock. Такая неоднозначность с аргументами (как показано выше), когда множество потоков могут передавать одни те же объекты в разные аргументы, может вызвать большую головную боль. К сожалению эта ситуация является очень распространенной, вызовы виртуальных методов, реализованных в пользовательском коде, так же могут произвести серию вызовов, которая может обзавестись блокировками в непредсказуемом порядке. Непредусмотренная комбинация блокировок постоянно рискует появлением deadlock.
Несколько Коварных Примеров Deadlock
Риск возникновения deadlock не ограничивается только взаимоисключающими критическими секциями. Есть и более коварные пути, на которых deadlock может возникнуть в вашей программе. Soft deadlock – когда кажется, что в вашем приложении произошел deadlock, но на самом деле программа просто застряла на выполнении операции с большим временем ожидания или возникли проблемы, мешающие продолжению работы метода. Например, интенсивные алгоритмы, выполняемые в GUI потоке, могут привести к полной потери отзывчивости приложения. В данном случае использования пула потоков было бы лучшим выбором (предпочтительно использовать новый компонент BackgroundWorker появившийся в .NET Framework 2.0).
Очень важно понимание, как скажется на производительности вызов того или иного метода в вашей программе, но на практике это оказывается очень сложным. Операция, которая вызывает другую, чья производительность имеет широкий диапазон времени выполнения, может привести к непредсказуемым задержкам, блокировкам и нагрузкам на процессор. Ситуация становится хуже, когда вызывающий метод до этого заблокировал какой либо общий ресурс, в этом случае, даже очень быстрые методы, в которых предусмотрен доступ до этого ресурса, будут ждать его освобождения. Части вашего приложения, имеющие превосходную производительность в обычных сценариях, могут ее лишиться, к примеру, если что либо произойдет в системном окружении. Сетевой обмен данными – прекрасный пример, обычно он имеет прекрасную производительность, но как только сетевого канала начинает нехватать для всех приложений запущенных на компьютере или сетевое подключение становится недоступным, производительность методов, использующих сетевой обмен, резко падает. Если вы разрабатывали приложения, использующие сетевой обмен, вы наверняка очень тщательно тестировали этот момент, к примеру, как ваше приложение поведет себя, когда вы отключите сетевой кабель от компьютера.
Когда ваш код выполняется в single-threaded apartment (STA http://www.introligator.org/articles/3/84 http://www.rsdn.ru/article/com/apartmnt.xml ) это эквивалентно эксклюзивной блокировке. Только один поток может обновлять GUI окна или выполнять код внутри STA апартамента. Такие потоки владеют очередью сообщений, в которую кладут информацию другие части приложения для последующей обработки. GUI используют эту очередь для получения информации, например запрос на перерисовку или запрос на закрытие окна. COM прокси используют очередь сообщений для вызова методов объектов, принадлежащих апартаментам. Любой код, выполняющийся в STA, ответственен за постоянный сбор и выполнение запросов из очереди сообщений, в противном случае очередь может засориться, что приведет к потере оперативности. В терминах Win32 это означает использование MsgWaitForSingleObject, MsgWaitForMultipleObjects (и их эквиваленты) или CoWaitForMultipleHandles APIs. Другие варианты, такие как WaitForSingleObject или WaitForMultipleObjects (и их эквиваленты) не будут прокачивать входящие сообщения.
Другими словами STA “lock” может быть освобожден только прокачкой очереди сообщений. Приложения, выполняющие операции с непредсказуемой производительностью в GUI потоке, без прокачки сообщений (как было замечено ранее), могут легко привести к deadlock. Хорошо написанные программы производят такую долгую обработку либо где то в другом месте, либо прокачивают сообщения каждый раз перед блокировкой, чтобы избежать проблем с отзывчивостью. К счастью CLR в управляемом коде прокачивает сообщения для вас (через вызовы Monitor.Enter, WaitHandle.WaitOne, FileStream.EndRead, Thread.Join, и так далее) помогая смягчить эту проблему.
Рассмотрим классический пример STA-induced deadlock. Поток работающий в STA апартаментах генерирует большое количество объектов и автоматически для них генерируются Runtime Callable Wrappers (RCWs http://msdn.microsoft.com/ru-ru/library/8bwh56xe.aspx ). Конечно RCWs должны быть утилизированы когда они становятся недоступны, в противном случае произойдет утечка памяти. Но утилизирующий поток CLR так же вынужден использовать прокси к STA чтобы освободить RCWs. Если STA не прокачивает очередь сообщений (к примеру поток заблокирован методами WaitForSingleObject или WaitForMultipleObjects ), то утилизирующий поток застрянет. Если STA перестанет прокачивать, это скажется на утилизирующем потоке, он будет замедляться и медленно наращивать количество ресурсов, которое ему необходимо утилизировать. Это в свою очередь может привести к out-of-memory и приложение упадет, или оно может перезапуститься (например, ASP.Net). Очевидно, что оба этих результата неудовлетворительны.
Фреймворки высокого уровня, такие как Windows Forms, Windows Presentation Foundation и COM скрывают от пользователя большую часть сложностей при работе с STA, однако они все же могут ошибиться и повести себя непредсказуемо, deadlock один из возможных результатов. Такие ошибки могут легко проскочить через этап тестирования приложения и возникнуть только при стрессовых нагрузках.
Различные типы deadlock, к сожалению, требуют различных методов борьбы. Остальная часть статьи будет посвящена исключительно deadlock критической секции. В CLR 2.0 появилась полезная утилита для отлавливания и отладки проблем связанных с STA. Новый Managed Debugging Assistant (MDA), ContextSwitchDeadlock был создан для отслеживания deadlocks включая межапартаментные переходы (cross-Apartment transitions). Если переход занимает более 60 секунд, CLR предполагает что произошел deadlock и натравливает на него MDA. Для более точной информации как включить и работать с MDA смотрите MSDN документацию.
Существует две основные стратегии, полезные при работе с deadlock критической секции.
Избежание взаимоблокировок. Если устранить всего одно из четырех условий возникновения deadlock (описанных выше), deadlock никогда не произойдет. Например, вы можете не блокировать ресурсы (как правило, это не представляется возможным), или устранить круговое ожидание. Это требует некой структурированной дисциплины, которая, к сожалению, может добавить множество накладных расходов при создании параллельного программного обеспечения.
Выявление и подавление deadlocks. Многие системы баз данных используют эту технику для пользовательских транзакций. Обнаружить deadlock не так сложно, гораздо сложнее правильно на него ответить. Вообще говоря, система обнаружения выбирает жертву (к примеру, один из потоков) и заставляет его произвести отмену текущей операции и сбросить все блокировки. Такая методика в управляемом коде может привести к нестабильности приложения, поэтому должна применяться с большой осторожностью.
Многие разработчики знают о возникновении возможности deadlock на теоретическом уровне, но очень не многие знают, как реально с ними бороться. Давайте взглянем на некоторые решения, которые попадают в обе описанные выше категории.
Избежание deadlocks с техникой Lock Leveling
Довольно распространенный подход для борьбы с deadlock в больших программных системах является техника под названием Lock Leveling (так же известная как Lock Hierarchy или Lock Ordering). Основная стратегия данного подхода заключается в том, что все блокировки имеют некий числовой уровень, так же этот числовой уровень зависит от архитектурного слоя, и после приобретения потоком блокировки он может блокировать ресурсы только более низкого уровня. Например, мы можем назначить общему ресурсу А уровень 10, а общему ресурсу Б уровень 5. Поток, вполне легально может сначала захватить ресурс А, а затем ресурс Б, но если в обратном порядке (так как уровень ресурса А (10) больше чем уровень ресурса Б (5)) произойдет исключение. Такая методика исключает возможность возникновения deadlock

И каждый нижележащий слой ничего не должен знать о вышележащем (к примеру, DAL ничего не знает о Business Logic и не может запускать его методов и так далее, но бывает это правило нарушается). Для того чтобы воспользоваться методикой Lock Leveling нам необходимо так же разделить на логические слои и числовые уровни блокировок, с верху вниз. Предположим в нашем приложении, должно хватить десяти заблокированных ресурсов, на слой, в одном (любом) методе, для его успешного выполнения. GUI - самый верхний слой, его числовые уровни блокировок будут в диапазоне от 30 до 21, Business Logic 20-11, DAL 10-1.
В случае вызова метода One все пройдет хорошо, так как в начале, блокируется объект с уровнем 30, а затем с уровнем 29. В случае вызова метода Two произойдет исключение, так как вначале блокируется объект с уровнем 30, следующим же заблокированным объектом, может быть только объект с уровнем 29 и ниже, а в данном случае происходит попытка вызова метода One, который вновь блокирует объект с уровнем 30.
Так же, эта методика повышает архитектурную целостность приложения, к примеру, затрудняет вызовы методов из нижележащего слоя в вышележащих. Предположим, что метод в DAL блокирует ресурс (уровень блокировки в DAL начинается с 10) и после пытается, в нарушении архитектуры, вызвать метод в Business Logic, который в свою очередь тоже блокирует какой либо ресурс (предположим с уровнем блокировки 20), в этом случае произойдет исключение.
Конечно, существуют различные варианты реализации Lock Leveling, в коде к статье (доступен для скачивания) представлен один из них, реализованный на C#. Использование одного экземпляра класса LeveledLock соответствует одной конструкции lock, работа с ним очень похожа на использование методов Enter и Exit класса System.Threading.Monitor. Во время создания экземпляра LeveledLock выставляется его числовой уровень блокировки.
В программе, как правило, все lock объекты объявляются в одном месте, например с использованием статических полей, доступных из любой части программы.
Реализация методов Enter и Exit класса LeveledLock, происходит с участием вызовов соответствующих методов приватного экземпляра System.Threading.Monitor. Также, с помощью Thread Local Storage (TLS) отслеживается последняя блокировка приобретенная потоком, благодаря этому обеспечивается проверка иерархии блокировок. Таким образом, можно полностью исключить возможность, приобретения блокировок в неправильном порядке. Удаляя возможность замкнутого ожидания, благодаря этому, удаляется любой шанс возникновения deadlock.
При попытке выполнения t2 произойдет LockLevelException исключение, в момент вызова метода lockA.Enter, исключение будет означать, что иерархия блокировок была нарушена. При использовании Lock Leveling, до поставки приложения пользователям, вы должны хорошо протестировать ваше приложение с применением агрессивного тестирования. Необработанное исключение так же неудовлетворительно для пользователей.
Обратите внимание, что метод Enter возвращает объект IDisposable, что позволяет использовать конструкцию using (очень похожую на lock блок). Затем, когда вы покидаете границы using блока, неявно вызывается метод Exit. Есть так же несколько других вариантов создания экземпляра LeveledLock, доступных через параметры конструктора. Параметр reentrant указывает, может ли эта блокировка быть взята повторно тем же потоком, который ей уже владеет (по умолчанию true). Параметр name, это не обязательный параметр, просто имя блокировки, которое может пригодиться при отладке.
По умолчанию intra-level блокировки недоступны, другими словами, если вы у вас заблокирован ресурс A с уровнем 10 и вы попытаетесь заблокировать ресурс C с уровнем 10, то у вас это не получится. Если разрешить подобное поведение, то это бы являлось грубым нарушением иерархии блокировок, как итог, потоки могли бы попытаться приобрести блокировки в различном порядке (A и C или C и A). Вы можете изменить это поведение, использовав перегруженную версию метода Enter, который принимает параметр permitIntraLevel. Но сделав это однажды, вы должны знать, что deadlock отныне возможен в вашем приложении. Тщательно проверяйте ваш код, что бы это явное нарушение иерархии блокировок не привело к deadlock. Но не зависимо от того, как тщательно вы проверили свой код, он никогда не будет таким надежным, как при строгой иерархии блокировок. Используйте эту функцию с особой осторожностью.
Работа с Lock Leveling не проходит без проблем. Динамическая композиция программных компонентов может привести к неожиданным runtime ошибкам. Если низкоуровневые компоненты удерживают блокировку и делают вызов виртуального метода, пользовательского компонента, и этот пользовательский компонент пытается получить блокировку на более высоком уровне, иерархия блокировок будет нарушена и произойдет исключение. Deadlock в этом случае не произойдет, но будет run-time ошибка. Это одна из причин, почему вызов виртуальных методов во время удерживания блокировок считается плохой практикой. Хотя, это лучше, чем риск возникновения deadlock, но это основная причина, почему базы данных не используют эту технику: Они должны поддерживать динамическую композицию пользовательских транзакций.
На практике, многие программные системы к концу разработки используют кучу одноуровневых блокировок, скорее всего, вы найдете в них вызовы использующие permitIntraLevel. Это происходит не из-за того, что разработчики были чрезвычайно умными или осторожными при использовании permitIntraLevel, а по тому, что методика Lock Leveling достаточно трудна и обременительна на практике. Гораздо проще пойти на риск deadlock или сделать вид, что его там нет и быть не может, предполагая, что он не произойдет ни при тестировании, ни после поставки приложения (в нашем случае, положившись на русский авось). Действительно, так поступить много проще, чем потратить несколько часов выполняя необходимый рефакторинг кода. Но хорошо построенные блокировки, при которых время удерживаемого ресурса минимально, а так же, когда при необходимости создаются защитные копии данных, все это может быть использовано, что бы сделать применение Lock Leveling проще.
Много систем использующий Lock Leveling отключают его при поставке приложения (в non-debug builds), чтобы избежать проблем связанных с лишней нагрузкой на производительность. Но это означает, что вы обязаны протестировать ваше приложение, чтобы найти все нарушения иерархии блокировок. Динамические компоненты делают эту задачу чрезвычайно трудной. Если вы выключаете Lock Leveling при поставке приложения, то один не протестированный или непредусмотренный вариант использования может привести к deadlock.
Выявление и прерывание deadlock.
Техники, обсуждаемые ранее, позволяют полностью избегать deadlock. Но обычно, существует большое количество уже написанного кода и этот код довольно трудно полностью адаптировать к использованию Lock Leveling. Обычно, когда появляется deadlock, он будет проявляться как зависшее приложение, которое может не привести к сбору отладочной информации и отправке сообщения разработчику. Но в идеальном случае, если система не может избежать deadlock, то было бы хорошо, чтобы она их обнаруживала и как можно быстрее отправляла отчет, со всеми необходимыми данными, для последующего устранения проблемы. Это возможно и без реализации Lock Leveling в вашем приложении.
Современные базы данных использую свою методику для борьбы с deadlock, но применение этих техник в управляемом приложении довольно сложно на практике. Когда конкурируют транзакции базы данных, пытаясь получить блокировку, ведущую к deadlock, база данных может откатить одну из них, освободить занимаемые ею ресурсы, чтобы другая транзакция могла продолжить работу, как будто ничего и не произошло. Приложение в этом случае может повторить запрос или предоставить возможность решать пользователю «Повтор / Отмена», либо как-то еще отреагировать на откат транзакции.
Но в заурядных приложениях, которые не были изначально подготовлены реагировать на deadlock, сбой (crash) процесса является единственным, что вы можете предпринять.
Управляемый код, находящийся под управлением SQL Server™ 2005 (hosted code) так же, как бонус, приобретает систему обнаружения deadlock, очень похожую на ту, что будет описана ниже. Любой управляемый код, размещенный на SQL Server™ 2005, неявно оборачивается в транзакции, и прекрасно работает со стандартным обнаружением deadlock в базах данных.
Довольно сложный код нужно написать, чтобы он умел обнаруживать deadlock в приложении и при обнаружении пытался, по одной, откатить блокировки. Например, если поток удерживает блокировку A и B и получает deadlock, когда пытается получить блокировку C, можно произвести откат на момент приобретения блокировки B и освободить B, немного подождать, чтобы другие потоки могли выполнить свою работу, потом вновь заблокировать B и попытаться заблокировать C. Если deadlock возникнет вновь, то можно попытаться откатиться до A и освободить ее, затем повторить выполнение метода.
CLR Hosting API может быть использована для введения (inject) собственной логики приобретения и освобождения мониторов. Я использовал эту возможность при создании примера хоста, который находит deadlock и смягчает его последствия (проект доступен в исходном коде к статье). Давайте рассмотрим поближе этот пример и посмотрим, как deadlock detection может работать на практике.
Алгоритмы.
Существует две общепринятых методики, для обнаружения deadlock: timeout-based и graph-based.
Timeout-Based: основано на времени, которое необходимо для получения блокировки.
При истечении время ожидания (timeout), вызывающий метод получает извещение. Иногда в виде исключения, в других случаях просто возвращается false (к примеру, в методе Monitor.TryEnter), которое позволяет программе или пользователю среагировать каким либо образом. Пространство имен System.Transactions использует эту модель в классе TransactionScopes, по умолчанию транзакции отменяются если выполнение превышает 60 секунд.
Основным недостатком данного подхода, это то, что deadlock обнаруживается позже, чем следовало бы, или длительные операции могут быть приняты за deadlock и прерваны. Кроме того, в моменты, когда программист решает, как поступить с deadlock, он может просто не знать, как правильно поступить или попытаться вновь взять блокировку, что приведет к бесконечному циклу.
Graph-Based: если у вас есть список потоков, которые находятся в активном ожидании, и перечень заблокированных ими ресурсов, вы можете составить график, показывающий кто кого ждет. Затем можно проанализировать данный график, если потоки в круговом ожидании, то произошел deadlock (однако, если какой либо поток в цикле использует Timeout-Based методику, при правильной реакции потока, deadlock может разрешиться самостоятельно). Это очень надежная стратегия, но довольно дорогостоящая в плане производительности.
В большинстве случаев комбинация этих методик может привести к хорошим результатам. К примеру, если произошел timeout, для проверки вы можете составить график. Это позволяет уменьшить значение timeout и создавать графики только в те моменты, когда в них требуется необходимость. Именно такой подход и применен в примере.
Далее Joe Duffy предлагает создать приложение Host, которое будет использовать CLR hosting API и C++. С помощью получившейся утилиты можно запускать .net приложения через командную строку (например deadhost.exe tests\test1.exe ) и находить deadlocks. Для более полной информации смотрите исходные коды к статье и оригинал статьи. А ниже будет описана более простая, пошаговая инструкция по выявлению deadlock, не только из запущенного приложения, но и с помощью анализа дампа памяти.
WinDbg + SosEx для поиска Deadlock
- Для начала необходимо установить Debugging Tools for Windows (windbg.exe)
- Зайдите на страницу https://en.wikipedia.org/wiki/Microsoft_Windows_SDK там есть таблица выпущенных версий Microsoft Windows SDK, со ссылками на скачивание.
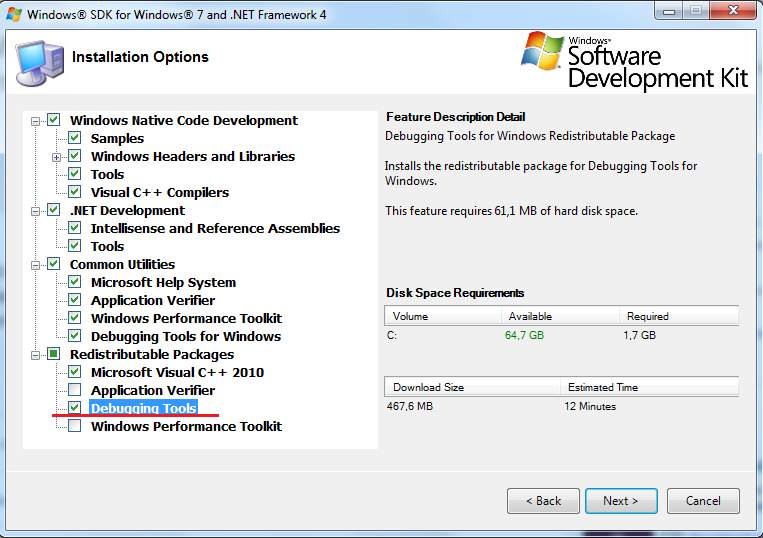
- Запустите установку и обязательно отметьте галочкой Debugging Tools
- Необходимо скачать Debugging Extension for Managed Code – SosEx, http://www.stevestechspot.com/

- Создадим консольное приложение SimpleDeadlock, которое будет впадать в deadlock практически в 100%
using System;using System.Threading;
namespace SimpleDeadlock{class Program{static object a = new object();static object b = new object();
public static void MethodOne(){lock (a){Thread.Sleep(100);lock (b){Console.WriteLine("Никогда не будет выведено на консоль (поток 1)");}}}
public static void MethodTwo(){lock (b){Thread.Sleep(100);lock (a){Console.WriteLine("Никогда не будет выведено на консоль (поток 2)");}}}
static void Main(string[] args){ThreadStart entryPointThread1 = MethodOne;ThreadStart entryPointThread2 = MethodTwo;
Thread one = new Thread(MethodOne);Thread two = new Thread(MethodTwo);
one.Start();two.Start();Console.WriteLine("Основной поток закончил работу.");}}} - Запустим его и убедимся, что произошел deadlock (приложение повисло)

- Запустим Task Manager, с помощью которого узнаем, что приложение 32 битное и его PID

- В меню пуск, с помощью поисковой строки находим нужный файл winbdg (в нашем случае x86) и запускаем его

- File -> Attack to a Process… -> выбираем наш процесс -> OK.

- 8. В открывшемся окне вы увидите несколько ошибок *** ERROR: Symbol file could not be found. Defaulted to export symbols for

- Для того чтобы получить символы отладки с сервера Microsoft просто введите команду
.sympath SRV*f:\localsymbols*http://msdl.microsoft.com/download/symbols
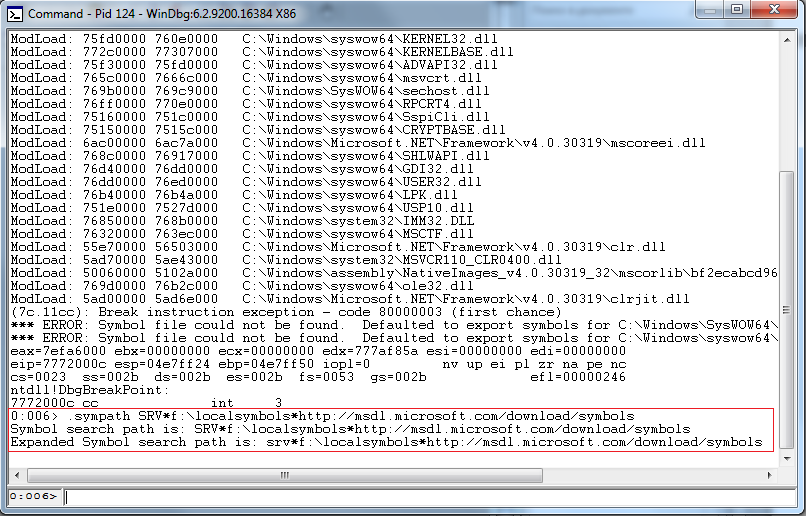
- Далее нужно загрузить расширение отладки SOS в отладчик, с помощью команды
.loadby sos clr
Результат выполнения команды:

- Распакуем скачанное нами ранее расширение SosEx (в моем случае я его распаковал по адресу C:\Sosex\32 ) и загрузим его с помощью команды
.load C:\SosEx\32\sosex.dll
Результат выполнения команды:

- Все готово к обнаружению deadlock, далее просто выполняем команду
!dlk
Результат выполнения команды:
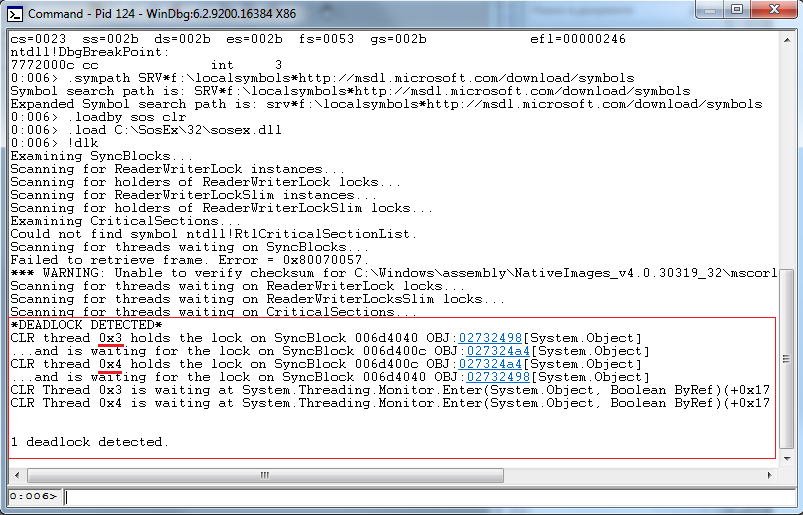
- Зафиксирован 1 deadlock, в нем участвуют потоки 0x3 и 0x4, для того что бы посмотреть стек вызова любого из этих потоков, просто введем команду
~4e !clrstack для потока 0x3
~5e !clrstack для потока 0x4
-
~4e !clrstack
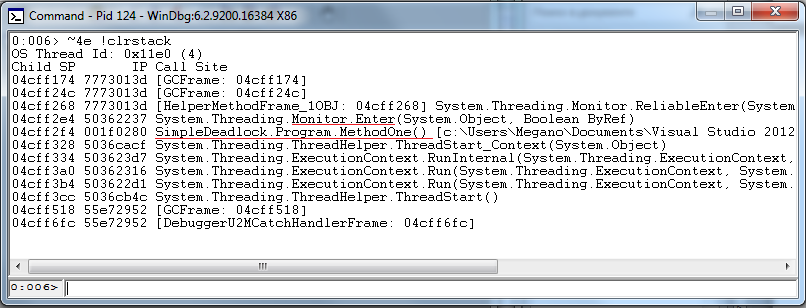
Из стека вызовов видно, что поток пытается получить блокировку в методе MethodOne -
~5e !clrstack

Из стека вызовов видно, что поток пытается получить блокировку в методе MethodTwo
Но что делать, если у вас нет возможности запустить приложение на своем компьютере и присоединить WinDbg к процессу? Вы можете попросить пользователя сделать полный дамп памяти, с помощью утилиты ProcDump, http://technet.microsoft.com/en-us/sysinternals/dd996900.aspx
В нашем случае нам нужен полный дамп 32 битного приложения, для этого подойдет командная строка: procdump -ma 124
-ma Write a dump file with all process memory. The default dump format only includes thread and handle information.
124 – PID процесса
И попросить переслать вам дамп, к примеру, по почте. А дальше все идентично, только подключаться нужно не к процессу, а к дампу памяти.
На этом все, удачи вам и спасибо что прочитали мою статью. Буду рад оставленным комментариям и новым постоянным читателям.
Александр Кобелев.
